HAL EtherCAT: one slave fine, two identical slaves issue
- Nico2017
- Offline
- Premium Member
-
- Posts: 153
- Thank you received: 26
some more test have led to this issue: kernel paging
If anyone know what it is about that would be great.
That happened while trying to load:
I have added the sdo before, but not sure if it is required or not.
Thank you,
Nicolas
Please Log in or Create an account to join the conversation.
- Nico2017
- Offline
- Premium Member
-
- Posts: 153
- Thank you received: 26
well using some xml without sdo I still kind of suffer of unstable behaviour. Sometime I manage to get the slaves into OP, sometimes not. Some other time I end up with the EtherCAT crashing when I close linuxcnc as shown by the kernel log:
Jan 24 12:18:45 machine kernel: [ 542.391306] EtherCAT WARNING 0-4: Invalid mailbox response for eoe0s4.
Jan 24 12:18:45 machine kernel: [ 542.927308] EtherCAT 0: Domain 0: 2 working counter changes - now 15/18
Jan 24 12:18:45 machine kernel: [ 542.927311] .
Jan 24 12:18:45 machine kernel: [ 542.933924] EtherCAT WARNING 0: 6 datagrams UNMATCHED!
Jan 24 12:18:46 machine kernel: [ 543.612944] EtherCAT 0: Slave states on main device: OP.
Jan 24 12:18:46 machine kernel: [ 543.931267] EtherCAT 0: Domain 0: Working counter changed to 18/18
Jan 24 12:18:46 machine kernel: [ 543.931270] .
Jan 24 12:19:12 machine kernel: [ 569.251426] EtherCAT 0: Master thread exited.
Jan 24 12:19:12 machine kernel: [ 569.251429] EtherCAT 0: Stopping EoE thread.
Jan 24 12:19:58 machine kernel: [ 616.015714] perf: interrupt took too long (2608 > 2500), lowering kernel.perf_event_max_sample_rate to 76500Not sure why also the working counter is 18 when I only got 6 slaves daisy chained (maybe 3 SM times 6)
I am kind of starting to think this is not related to my slaves and maybe my computer hardware. I am using the generic ethercat master.
Any hint would be helpful.
Nicolas
Edit:
Hi, apparently this additional issue could be from overheating processors. If anyone could confirm this? I think this is not the main problem of this thread but might come time to time on top as the computer is working hard to make the EtherCAT working.
New edit:
this additional issue is actually relate to the version of the EtherCAT master from the ec-debianize. Reinstalling the newest one made things ore stable. But I am still not able to make two EPacks slave communicate with the master on the same loop.
Please Log in or Create an account to join the conversation.
- chimeno
- Offline
- Elite Member
-
- Posts: 295
- Thank you received: 125
What would be the different options for refClockSyncCycles = "4"? Can it be eliminated if all slaves are in free run mode?
to start I would leave them in refClockSyncCycles = "1000"
Thank you for passing the project on TWINCT3, I see that the communication of the device is done through the implementation of the mailbox protocol "Ethernet over EtherCAT" (EoE), I think that in the new version of igh etherlab some problems were solved in this regard.
You should also configure the EOE section?
You can also perform this test, turn on the device and read which PDO has pre-defined settings? using the ethercat pdos command? can you show me
greeting
Chimeno
Please Log in or Create an account to join the conversation.
- Nico2017
- Offline
- Premium Member
-
- Posts: 153
- Thank you received: 26
here are the default pdos at start up:
ethercat pdos
=== Master 0, Slave 0 ===
SM0: PhysAddr 0x1000, DefaultSize 1472, ControlRegister 0x26, Enable 1
SM1: PhysAddr 0x15c0, DefaultSize 1472, ControlRegister 0x22, Enable 1
SM2: PhysAddr 0x1b80, DefaultSize 32, ControlRegister 0x64, Enable 1
RxPDO 0x1600 "Module RxPDO default mapping"
PDO entry 0x7001:09, 32 bit, "Setpoint provider Remote 2"
RxPDO 0x1601 "Module RxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
RxPDO 0x17ff "Device RxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
SM3: PhysAddr 0x1dc0, DefaultSize 62, ControlRegister 0x20, Enable 1
TxPDO 0x1a00 "Module TxPDO default mapping"
PDO entry 0xf390:00, 8 bit, "Latched Exception Status"
PDO entry 0xf380:00, 8 bit, "Active Exception Status"
PDO entry 0x6002:01, 32 bit, "Control Process Value"
PDO entry 0x6002:02, 32 bit, "Control Main Setpoint"
PDO entry 0x6000:05, 32 bit, "Network Current"
PDO entry 0x6000:0a, 32 bit, "Network Load Voltage"
PDO entry 0xf391:01, 32 bit, "Latched Device Warning Details"
PDO entry 0xf393:01, 32 bit, "Latched Device Error Details"
TxPDO 0x1a01 "Module TxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
TxPDO 0x1bfe "Device TxPDO default mapping"
PDO entry 0xf397:01, 32 bit, "Latched Global Device Error Details"
TxPDO 0x1bff "Device TxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
=== Master 0, Slave 1 ===
SM0: PhysAddr 0x1000, DefaultSize 1472, ControlRegister 0x26, Enable 1
SM1: PhysAddr 0x15c0, DefaultSize 1472, ControlRegister 0x22, Enable 1
SM2: PhysAddr 0x1b80, DefaultSize 32, ControlRegister 0x64, Enable 1
RxPDO 0x1600 "Module RxPDO default mapping"
PDO entry 0x7001:09, 32 bit, "Setpoint provider Remote 2"
RxPDO 0x1601 "Module RxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
RxPDO 0x17ff "Device RxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
SM3: PhysAddr 0x1dc0, DefaultSize 62, ControlRegister 0x20, Enable 1
TxPDO 0x1a00 "Module TxPDO default mapping"
PDO entry 0xf390:00, 8 bit, "Latched Exception Status"
PDO entry 0xf380:00, 8 bit, "Active Exception Status"
PDO entry 0x6002:01, 32 bit, "Control Process Value"
PDO entry 0x6002:02, 32 bit, "Control Main Setpoint"
PDO entry 0x6000:05, 32 bit, "Network Current"
PDO entry 0x6000:0a, 32 bit, "Network Load Voltage"
PDO entry 0xf391:01, 32 bit, "Latched Device Warning Details"
PDO entry 0xf393:01, 32 bit, "Latched Device Error Details"
TxPDO 0x1a01 "Module TxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
TxPDO 0x1bfe "Device TxPDO default mapping"
PDO entry 0xf397:01, 32 bit, "Latched Global Device Error Details"
TxPDO 0x1bff "Device TxPDO user specific mapping"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"
PDO entry 0x0000:00, 16 bit, "Gap"That is why originally I had a config file with all those non defined pdos "Gap" definitions.
For the ethercat I am using:
ethercat version
IgH EtherCAT master 1.5.2 unknownTo come back to the points you asked for:
, if I keep or remove it, it does not look to have any other effect. Again not really sure if it is usefull if those slaves are supposed to work in free run mode.refClockSyncCycles = "1000"
I am only using EoE to use the proprietary tool under windows to connect myself to change some parameters in the power controller. I have to activate it with TwinCAT that is why you can see it in the project. Although, from the ethercat doucmentation:You should also configure the EOE section?
, so that could be another way to get those slave into OP mode.Automatic Configuration: By default, slaves are left in PREOP state, if no con-figuration is applied. If an EoE interface link is set to “up”, the requested slave’sapplication-layer state is automatically set to OP
- ethercat pdos see above
At initial start up, all my slaves are going into PREOP but the EPacks slaves are shown into PREOP with an error E. I have to manually force them to
ethercat state PREOPethercat slavesThe manufacturer has guided towards modifying the watchdog parameter. So I have been adding
to the slave xml config, but it does not seem to get the normal behaviour neither when closing linuxcnc (EPack slave goes into PREOP with error). To be honest, not sure which value should be entered and what are the units of time for the watchdog.<watchdog divider="1000" intervals="100"/>
Nicolas
Please Log in or Create an account to join the conversation.
- chimeno
- Offline
- Elite Member
-
- Posts: 295
- Thank you received: 125
I do not think so, I have forced ventilation in the whole computer and it does not usually get too hot.Hi, apparently this additional issue could be from overheating processors. If anyone could confirm this? I think this is not the main problem of this thread but might come time to time on top as the computer is working hard to make the EtherCAT working.
For the ethercat I am using:
etherlabmaster_1.5.2+20180317hg9e65f7-2_amd64.deb, if I keep or remove it, it does not look to have any other effect. Again not really sure if it is usefull if those slaves are supposed to work in free run mode.
if you have no effect on the devices, only meant every time the Ethercat frame is restarted, I usually stop it at the beginning in the tests to give the whole time, but if it affects "watchdog"
Solo estoy usando EoE para usar la herramienta patentada en Windows para conectarme y cambiar algunos parámetros en el controlador de energía. Tengo que activarlo con TwinCAT, por eso puedes verlo en el proyecto. Aunque, de la documentación de ethercat:
Ok, I thought the configuration had to be loaded every time the device was initialized.
At initial start up, all my slaves are going into PREOP but the EPacks slaves are shown into PREOP with an error E. I have to manually force them to
to clear the error before launching my linuxcnc with ethercat components. Same thing when I turn off linuxcnc, the EPack slaves go back into PREOP with an error E if I do
you don't have to worry about the device when it is in PREO-OP E mode before starting linuxcnc-ethercat, since every time linuxcnc-ethercat starts it restarts all the devices and reconfigures, the errors have to disappear once the linuxcnc-ethercat application is started, you also don't have to worry when you close the application, since linuxcnc-ethercat does not close the frame and is left on the air.
The manufacturer has guided towards modifying the watchdog parameter. So I have been adding
<watchdog divider="2500" intervals="2000"/>can you try this Attached in an .xml file are changes without importance.
also another test that you can do, is to try everything in a single MASTER and change the order of the devices.
Greeting
Chimeno
Please Log in or Create an account to join the conversation.
- Nico2017
- Offline
- Premium Member
-
- Posts: 153
- Thank you received: 26
so you have just added a watchdog and changed the hal type to u32 for all the pins. Is that it?
I will give it a try later on,
Nicolas
Edit:
Using the u32 does significantly reduce the number of pins used and overall hal memory used (indicated by halcmd status).
But I still get an unstable behaviour.
When I put the non mandatory pdos (empty ones with 0) I manage to go into OP state most of the time but when I put only the mandatory ones, removing the Gap with the 0000 index and subindex, I do not manage to switch to OP most of the time.
Both configuration can actually crash the OS when at the line Ethercat releasing EoE.
Please Log in or Create an account to join the conversation.
- chimeno
- Offline
- Elite Member
-
- Posts: 295
- Thank you received: 125
You can try this configuration that attached, I would have to change the configuration to the factory default section 1C32 and 1C33, I am reading the manual a little more and it only works in free operation mode, but the data exchange must be synchronized within 50 hz at 10 ms 60hz at 8ms.
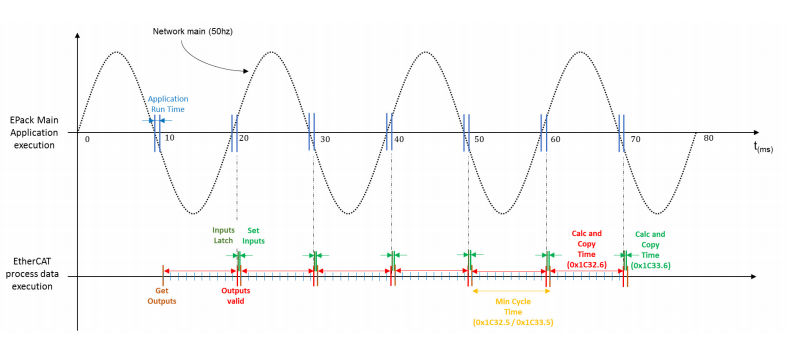
there can also only be a total in the 32 outputs SM2 and in the 64 inputs SM3
I don't know if this can help or guide you
regards
Chimeno
Please Log in or Create an account to join the conversation.
- Nico2017
- Offline
- Premium Member
-
- Posts: 153
- Thank you received: 26
thanks for your reply, I went extensively over the user guide too.
The synchronisation is a bit specific:
- when the mains are on, this is following what you described on your post
- when the mains are off, (not connected, see note on the same page you took the screenshot from), the EPack runs cyclically every 18ms
Moreover regarding the size of the PDO limitation, is it per slave or per sync manager? If it is the second, does this imply that you have a limit on the number of EPack slave with identical configuration that can be daisy chained?
Thank you again for your help,
Nicolas
Please Log in or Create an account to join the conversation.
- chimeno
- Offline
- Elite Member
-
- Posts: 295
- Thank you received: 125
Hi Nico2017Moreover regarding the size of the PDO limitation, is it per slave or per sync manager? If it is the second, does this imply that you have a limit on the number of EPack slave with identical configuration that can be daisy chained?
It's for slave, I tell you because in the project that you passed me from TWINCAT3 on the SM2 OUTPUT you have 33, attached screenshot.
The synchronisation is a bit specific:
when the mains are on, this is following what you described on your post
when the mains are off, (not connected, see note on the same page you took the screenshot from), the EPack runs cyclically every 18ms
In my case the mains could either be on or off, the emergency stop de-powering the main for instance. Most of the test I have done so far were with the mains off, and I already observe really strange behaviour of this EPack slave. It does not go into SAFFEOP when the computer start, but goes into SAFEOP with Error. Same thing after closing linuxcnc if it manages to launch it. What would be the 18ms indicating regarding to the EtherCAT config. Has my appTimePeriod to be higher or lower than this?
the issue of synchronism not having the device I can not do tests, I still bite the guard dog?
<master idx = "0" appTimePeriod = "1000000" refClockSyncCycles = "1000">
<slave idx = "0" type = "generic" vid = "000001bc" pid = "0000e1a2" configPdos = "true" name = "EPZ1">
<watchdog divider = "2000" intervals = "2000" />I think you should first set the cycle time, before trying to go to OP, write 1C32.8 = 1 - 1C33.8 = 1 measure time, write 1C32.6 = 1 - 1C33.6 = 1 copy time, then return to set them to 0 and take it to OP, can I be wrong? Never had to do this kind of synchronism.
Greeting
Chimeno
Please Log in or Create an account to join the conversation.