LinuxCNC Features - a kind of NGCGUI
- andypugh
-

- Offline
- Moderator
-

- Posts: 19875
- Thank you received: 4642
When do you think you will publish it? I still have some ideas to do in engraving feature (text on arc), but wont be able to finish it before next weekend
I think that there is a strong argument that this feature should be brought into the main LinuxCNC repository. This would make version control and collaborative working more structured (I am not going to claim "easier" because how easy it would be depends on whether you know Git or not.)
Whether it belongs in linuxcnc.git or linuxcnc-wizards.git is something I don't feel qualified to answer.
Please Log in or Create an account to join the conversation.
- mariusl
-

- Offline
- Platinum Member
-
I think that there is a strong argument that this feature should be brought into the main LinuxCNC repository. This would make version control and collaborative working more structured (I am not going to claim "easier" because how easy it would be depends on whether you know Git or not.)
I second that notion Andy. I think it is great work being done here. It will also serve as a motivator to other developers.
Regards
Marius
www.bluearccnc.com
Please Log in or Create an account to join the conversation.
- FernV
-

- Offline
- Platinum Member
-
- Posts: 457
- Thank you received: 124
Subprocessing is something I am really not familiar with and I really do not master it so maybe this is a cue to solve the problem
Instead of adding
[COMMAND]
content = /lib/engrave-feature -X#param_x -Y#param_y ...
add in
[CALL]
content = <subprocess>/lib/engrave-feature -X#param_x -Y#param_y ...</subprocess>
#or the right command, I do not know
then in
def process(self, s) :
.
.
.
for p in self.param :
if "call" in p.attr and "value" in p.attr :
s = re.sub(r"%s([^A-Za-z0-9_]|$)" % (re.escape(p.attr["call"])), r"%s\1" % (p.attr["value"]), s)
#next line added after params are replaced with their values
s = re.sub(r"(?ims)(<subprocess>(.*?)</subprocess>)", exec_callback, s)Fern
Please Log in or Create an account to join the conversation.
- fixer
- Offline
- Premium Member
-
- Posts: 132
- Thank you received: 27
Depending on layout it could load differently. The idea is being easier to find the param a user wants to change. I think of any user, beginner or senior alike, not just you.
Yeah, I forgot to add "my oppinion". I tottaly support you, you are doing a fantastic work here, Features will evolve over time and will get more compicated, so this is of course a good thing. But, with small set of parameters, I think that it it is easier to work if you have a good overview of all params.
I am by no means a software developer,I will leave this to someone else. I dont know python enough to solve this. Until then I will use it as it is now.I understand what you are doing but have you tried using <exec>subprocess("/lib/engrave-feature ...")</exec> in [CALL] content ? In f.process it would call 'exec_callback'.
I would try this way.
I would also modify engrave-feature.py to add some functionnality like : horizontal align (left, center or right), vertical align (top, center or bottom) that would require a first step of calculating width and height BEFORE creating the gcode. And instead of using yscale I would use 'Height'. I think xscale is OK.
Try to integrate it as much as possible so we can engrave some text in the center of a workpiece, engrave an ellipse around it then cut the workpiece as a rectangle with styled corners
Can do, and I will do. Trigonometry I can, serious programming in anything higher than embedded C I cannot. Have to do some reorganisation in code first, move all calculations to g-code, so you can use parametric g code,... I wont post anything until i have something near finnished.
Please Log in or Create an account to join the conversation.
- FernV
-
- Offline
- Platinum Member
-
- Posts: 457
- Thank you received: 124
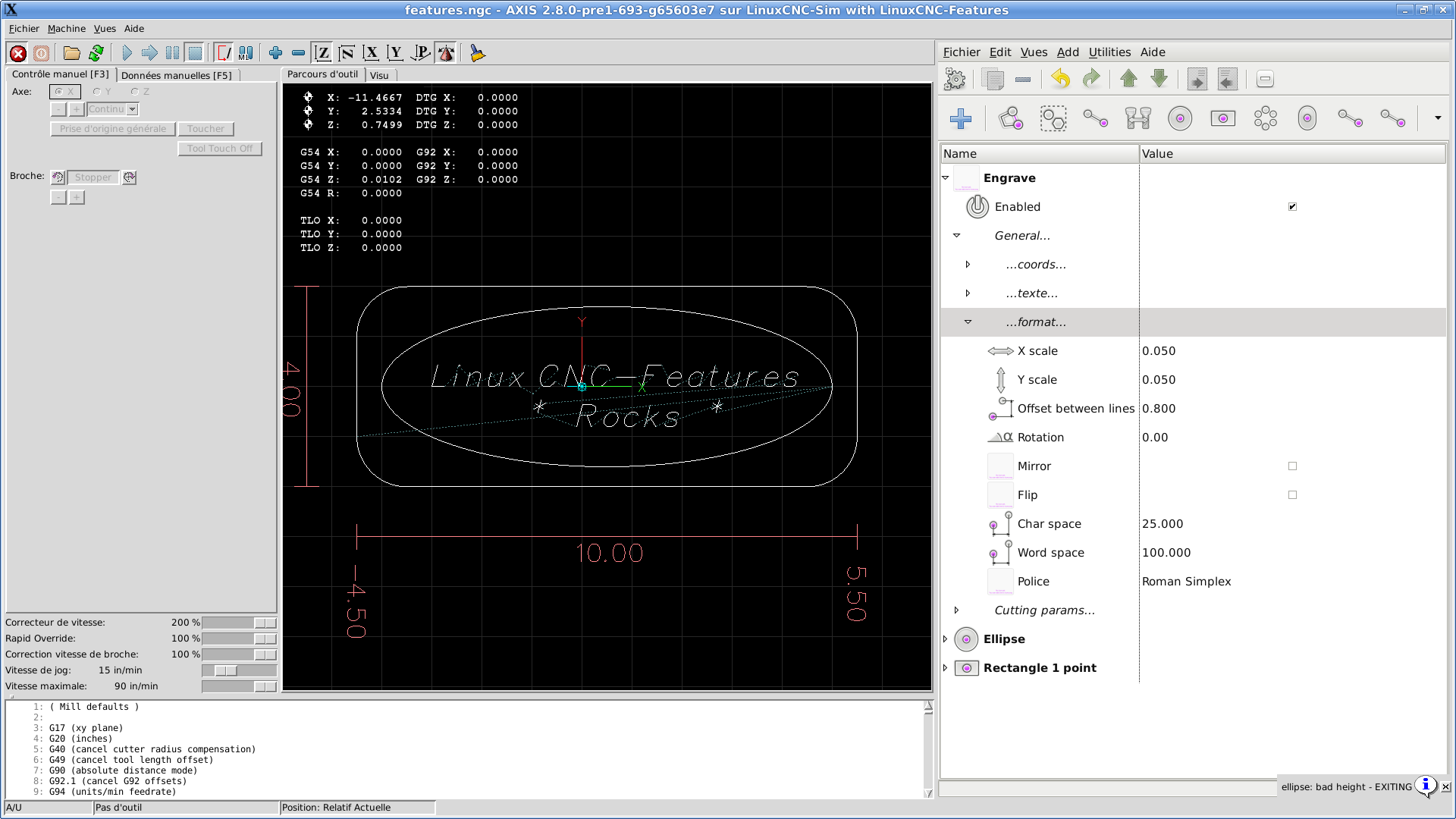
I succeeded with the integration of engraving in Features.
One screenshot
Simply replace process function with this code
def process(self, s) :
def eval_callback(m) :
return str(eval(m.group(2), globals(), {"self":self}))
def exec_callback(m) :
s = m.group(2)
# strip starting spaces
s = s.replace("\t", " ")
i = 1e10
for l in s.split("\n") :
if l.strip() != "" :
i = min(i, len(l) - len(l.lstrip()))
if i < 1e10 :
res = ""
for l in s.split("\n") :
res += l[i:] + "\n"
s = res
old_stdout = sys.stdout
redirected_output = StringIO()
sys.stdout = redirected_output
exec(s) in {"self":self}
sys.stdout = old_stdout
redirected_output.reset()
out = str(redirected_output.read())
return out
def subprocess_callback(m) :
s = m.group(2)
# strip starting spaces
s = s.replace("\t", " ")
i = 1e10
for l in s.split("\n") :
if l.strip() != "" :
i = min(i, len(l) - len(l.lstrip()))
if i < 1e10 :
res = ""
for l in s.split("\n") :
res += l[i:] + "\n"
s = res
return subprocess.check_output([s], shell = True)
def import_callback(m) :
fname = m.group(2)
if fname != None :
try :
return str(open(fname).read())
except :
StatusBar.push(SB_File_context_id, _("File not found : %s") % fname)
else :
mess_dlg(_("File not found : %(f)s in %(p)s" % {"f":fname, "p":(XML_DIR)}))
raise IOError("IOError File not found : %(f)s in %(p)s" % {"f":fname, "p":(XML_DIR)})
s = re.sub(r"(?i)(<import>(.*?)</import>)", import_callback, s)
s = re.sub(r"(?i)(<eval>(.*?)</eval>)", eval_callback, s)
s = re.sub(r"(?ims)(<exec>(.*?)</exec>)", exec_callback, s)
for p in self.param :
if "call" in p.attr and "value" in p.attr :
s = re.sub(r"%s([^A-Za-z0-9_]|$)" % (re.escape(p.attr["call"])), r"%s\1" % (p.attr["value"]), s)
s = re.sub(r"(?ims)(<subprocess>(.*?)</subprocess>)", subprocess_callback, s)
s = re.sub(r"#self_id", "%s" % self.get_attr("id"), s)
return s
In mz_engrave.ini
Delete the [COMMAND] block completely
Change the [CALL] with this
[CALL]
content =
o<#self_id> if [#param_ena]
<subprocess>./lib/engrave-feature.py -X#param_x -Y#param_y -S#param_xscale -s#param_yscale -Z#param_s -D#param_dpt -A#param_rot -W#param_word -C#param_char -M#param_mirror -F#param_flip -f#param_font -0'#param_line0 ' -1'#param_line1 ' -2'#param_line2 ' -3'#param_line3 ' -4'#param_line4 ' -5'#param_line5 ' -6'#param_line6 ' -7'#param_line7 ' -8'#param_line8 ' -9'#param_line9 ' -y'#param_yoff'</subprocess>
o<#self_id> endifThat is all.
I agree some improvements can be made to engrave.py. Some small changes were made to integrate it but more functionnalities can be added. It can also be optimized at some places and I think variables like #1000, #28, etc should be replaced with significant names, same for o9000 sub. I know it works as is but it would make it much more human readable when needed.
Regards
Fern
Please Log in or Create an account to join the conversation.
- fixer
- Offline
- Premium Member
-
- Posts: 132
- Thank you received: 27
Great, will try it out!Hi Mit,
I succeeded with the integration of engraving in Features.
I agree some improvements can be made to engrave.py. Some small changes were made to integrate it but more functionnalities can be added. It can also be optimized at some places and I think variables like #1000, #28, etc should be replaced with significant names, same for o9000 sub. I know it works as is but it would make it much more human readable when needed.
Regards
Fern
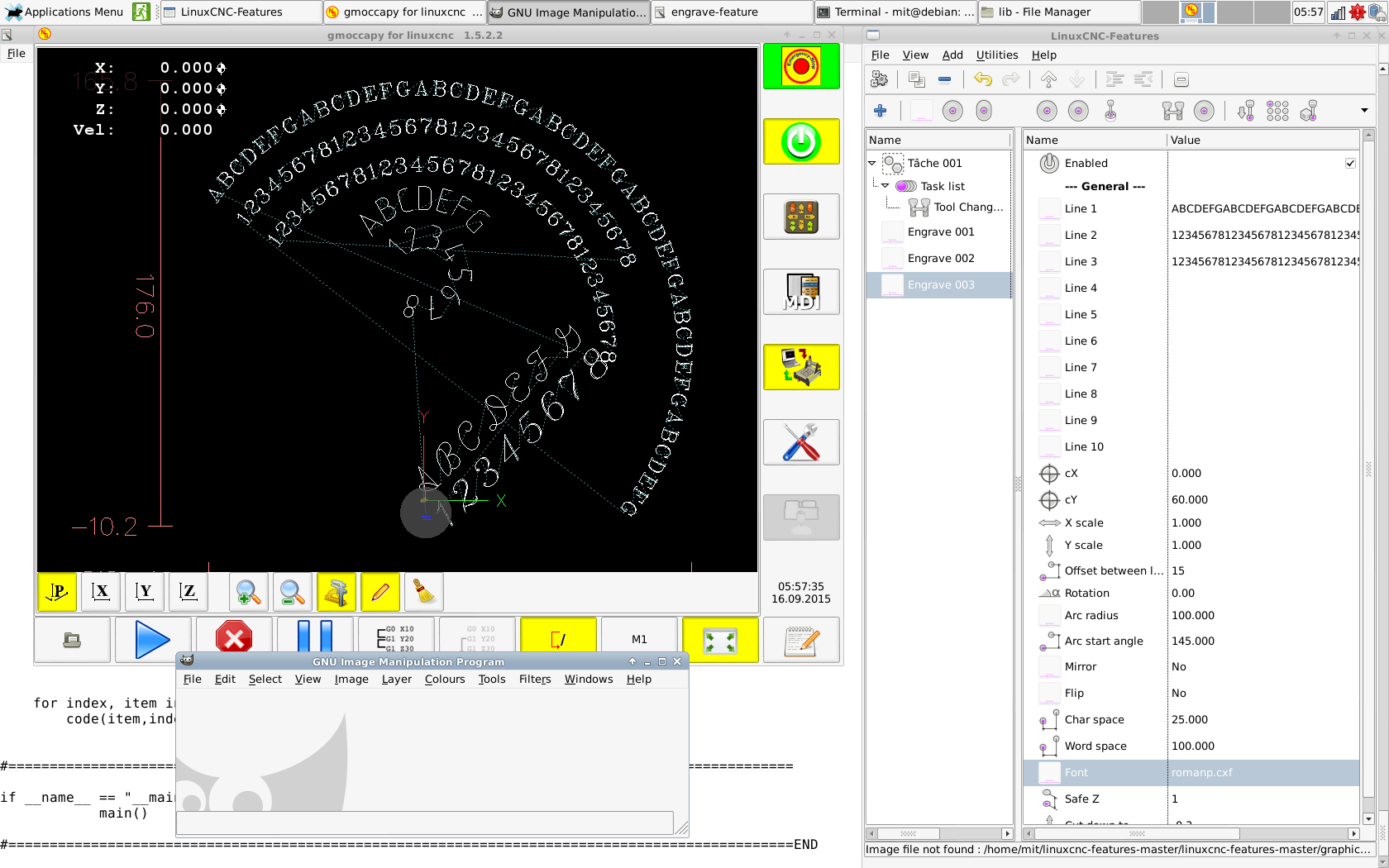
It will receive a big rework. You will be able to postion text referenced by angles, center, center of arc, align text keft, right, center, all parameters will be visible in G code, all those variables and sub are already renamed. If anyone can think of anything else please share you ideas.
Please Log in or Create an account to join the conversation.
- FernV
-
- Offline
- Platinum Member
-
- Posts: 457
- Thank you received: 124
WOW! You code faster than your shadow...
A few suggestion,
- Replace 'Y scale' with 'Text Height' or 'Row Height' either in mm or inch
- X scale should relate to 'Text Height'
- Replace 'Offset between lines' with 'Line spacing', a factor to 'Text Height'
- It is not clear what Char Space and Word Space values must be set to, maybe it should also be a factor to height
I had a look last night at Truetype Tracer www.timeguy.com/cradek/01276453959
It could be used easily. Not as many options as engrave.py yet but well designed and written in c, could be updated for our use.
Advantages are it can use any TrueType font and G-Code executes a lot faster.
I am considering it but with your talents, would you take a look ? Let me know what you think
Regards
Fern
Please Log in or Create an account to join the conversation.
- fixer
- Offline
- Premium Member
-
- Posts: 132
- Thank you received: 27
Suggegtions taken into consideration. I belive i will do just like that, everything will be relative to text height wich you will set in machine units.
Truetype fonts are surface based - TTT generates code that cuts around those surfaces, wich makes it unusable for small engravings. CXF fonts, on the other hand were designed intentionally for use with CAD-CAM-CNC.
There are enough fonts in qcad repo, so i think there is no need to have support for anything else. Plus, if you find any other good single line font, there is a tool for converting to cxf format somewhere. Haven't tried that though.
I would include TrueTypeTracere in Features anyway, one may find it usable. Since a simple ini, thanks to you, is all that it is needed.
Please Log in or Create an account to join the conversation.
- fixer
- Offline
- Premium Member
-
- Posts: 132
- Thank you received: 27
But, of course I have come to the limitations of my programming knowledge. I have trouble dealing with unicode strings. Until I pass ASCII chars to python script it works, but when I use any of non ascii char, it starts to throw exceptions...
Is anybody here willing to help with this issue?
And we will need some kind of CXF font optimizer - some chars, that could be made with single or only a few strokes are divided in many different strokes, each next stroke starting away from the last stroke end. The produced g-code is then full of unwanted rapid moves... I think it would be best to write a script, that would optimize the font and then write it back in cxf format. If anyone is interesed to help here I can send the collection of 45 fonts that I have currently. CXF format is pretty easy to read in, it would just need some kind of "sort points by distance" alghoritm.
Please Log in or Create an account to join the conversation.
- FernV
-
- Offline
- Platinum Member
-
- Posts: 457
- Thank you received: 124
There is no rush on this project, we all understand you may have other priorities.
I am sorry, my knowledge is less than yours on this matterI am a little busy lately, but am still working on engrave feature slowly. I have some progress, now it supports QCAD 3 fonts, have a working ttf2cxf tool. I use xy-rotate from features instead o9000, almost everything works ok.
But, of course I have come to the limitations of my programming knowledge. I have trouble dealing with unicode strings. Until I pass ASCII chars to python script it works, but when I use any of non ascii char, it starts to throw exceptions...
Is anybody here willing to help with this issue?
Just like you, I also have other priorities in finalizing FeaturesAnd we will need some kind of CXF font optimizer - some chars, that could be made with single or only a few strokes are divided in many different strokes, each next stroke starting away from the last stroke end. The produced g-code is then full of unwanted rapid moves... I think it would be best to write a script, that would optimize the font and then write it back in cxf format. If anyone is interesed to help here I can send the collection of 45 fonts that I have currently. CXF format is pretty easy to read in, it would just need some kind of "sort points by distance" alghoritm.
I added the possibility to open a file chooser dialog for any type of files. Just a new datatype supported.
[PARAM_FONT]
name = Font
type = filename
patterns = *.cxf:*.ttf
mime_types = text/ttf
filter_name = Supported Fonts
tool_tip = Select a Font file
value = /usr/share/fonts/truetype/liberation/LiberationSans-Bold.ttfSince we can not know what fonts someone has on his computer, we can not use a combo unless including all the font files in a specific directory.
Features integrates very well with gmoccapy now. I am solving bugs I was not aware of in the ini files when using metric and it is getting closer and closer to be released.
Regards
Fern
Please Log in or Create an account to join the conversation.