Ethercat random jitter fix
- Hakan
- Offline
- Platinum Member
-
- Posts: 1317
- Thank you received: 453
Here is a listing of the first five lines, from lcec.write-all.
Data is cycle number, pll-err, reference clock time, application time
0 0 3536553781 142022168
1 0 3536553781 143094900
2 1629533556 2808528640 144063093
3 0 2809491813 2810488578
4 10994 2810477584 2811488510Now, speculating a bit, the clock is not changed right away, instead the clock is slowly changed
and the slave maintains a system time offset register 0x92c. It can then report and accurate
time by using the clock, that is off until in sync, and add the system time offset.
Must say it is speculation this though.
Anyway, the initial time setting in rt_app_main, or possibly the first few rounds in lcec_write should be looked at.
Please Log in or Create an account to join the conversation.
- papagno-source
- Offline
- Elite Member
-
- Posts: 170
- Thank you received: 13
Please Log in or Create an account to join the conversation.
- rodw
-

- Away
- Platinum Member
-
- Posts: 11995
- Thank you received: 4084
- Version 1.5.2 vs. Modern Branches: The reason version 1.5.2 felt "smoother" is because it often operated in Free Run mode. It wasn't strictly enforcing nanosecond-precise timing, so it never performed the violent corrections ("snaps") seen in newer, more precise versions.
- The "Startup Snap": Grandixximo’s branch is designed to solve Phase Drift (especially common at a 1ms servo thread). To get the PC and the network in phase, the driver forces a massive time jump (the 1.6s jump Hakan lists) at startup.
- Cheap Hardware Sensitivity: Modern, lower-cost EtherCAT servos have lower-quality internal clocks and smaller "sync windows." Unlike premium hardware, they cannot "soak up" timing errors and will grind or stutter the moment the Master clock shifts
Deployment Fixes
- Slave 0 Hierarchy: The first DC-capable device in the chain is the Reference Clock. For industrial stability, this should always be a high-quality device (like a Beckhoff EK1100) rather than a budget drive.
- The "Machine On" Interlock: You should never enable the machine (allow physical motion) until the system is "in range." The drives should be kept in a disabled state while the driver performs its initial 1.6s "snap" Hakan shows
- The "Safe Window" Logic: Implement a HAL interlock that monitors thepin. Hold the enable signals low until the error is stable (maybe for a few seconds)
pll_err
Please Log in or Create an account to join the conversation.
- endian
-

- Offline
- Platinum Member
-
- Posts: 336
- Thank you received: 132
I think its very weird now ... I remeber that times when everybody here are running deb10 with 4.19 kernels and 1.5.2 master version... there was no timing problem at all either at startup of lcnc... I single grinding from the Kollmorgen S300 drivers at 1ms single time but I solved it by installing native driver and editing the assignActivate of DC from 0x0300 to 0x730 and every grinding sound was gone ... that drivers are pretty sensitive DC stuff really same to AX5000 from beckhoff(I do not know if I go right that time ... ) I am running well tunned i5 with around 2us latency beckhoff IPC but startup delay are present nowdays... sometime even AX5000 drivers are not became OP because of this synchronization issue I think ... somewhere there is the original thread of lcec from sascha and there is really really really recommended to start the physical ebus with the DC capable device, best practise is one of the axis I can not see under the hood of lcec because its not my cup of tea but, it should be real breakthrough it this tailchasing will be doneSo I am not really qualified here but I've had some ideas which I explored.The Core Issues
The "Safe Window" Logic: Implement a HAL interlock that monitors the
- Version 1.5.2 vs. Modern Branches: The reason version 1.5.2 felt "smoother" is because it often operated in Free Run mode. It wasn't strictly enforcing nanosecond-precise timing, so it never performed the violent corrections ("snaps") seen in newer, more precise versions.
- The "Startup Snap": Grandixximo’s branch is designed to solve Phase Drift (especially common at a 1ms servo thread). To get the PC and the network in phase, the driver forces a massive time jump (the 1.6s jump Hakan lists) at startup.
- Cheap Hardware Sensitivity: Modern, lower-cost EtherCAT servos have lower-quality internal clocks and smaller "sync windows." Unlike premium hardware, they cannot "soak up" timing errors and will grind or stutter the moment the Master clock shifts
Deployment Fixes
- Slave 0 Hierarchy: The first DC-capable device in the chain is the Reference Clock. For industrial stability, this should always be a high-quality device (like a Beckhoff EK1100) rather than a budget drive.
- The "Machine On" Interlock: You should never enable the machine (allow physical motion) until the system is "in range." The drives should be kept in a disabled state while the driver performs its initial 1.6s "snap" Hakan shows
pll_err pin.
Hold the enable signals low until the error is stable (maybe for a few seconds) Yes, some AI input here but this is a summary of a detailed conversation I had with my well trained assistant
Please Log in or Create an account to join the conversation.
- grandixximo
-
 Topic Author
Topic Author
- Offline
- Elite Member
-
- Posts: 307
- Thank you received: 367
Thanks for the trace, it pointed straight at the bug. I reproduced your observation on my hardware and the root cause is exactly the "bad initial reference time" you flagged, but only in M2R mode. R2M is unaffected because it only writes the ref clock (sync_reference_clock_to) and never reads it back.
I added a small debug capture inside the dcsync callbacks (same columns as yours: cycle, pll-err, ref_time_lo, app_time) and logged the first 10 cycles. Before the fix on M2R:
# cycle pll_err ref_time_lo app_time_ns app_time_lo
0 0 1875535147 829958931561087328 1037861216
1 0 1037346343 829958931562087328 1038861216
2 -385754 1038312400 829958935857087328 1038893920
3 -382546 1039366179 829958935858087328 1039893920
...Between cycles 1 and 2, app_time_ns jumps by 4,295,000,000 ns (4.3sec). Same shape as your lcec.write-all trace.
Mechanism, walked through the code:
1. Cycle 0 pre_send reads ref_time_lo = 1,875,535,147. At this point our first frame carrying ecrt_master_application_time() has NOT yet been sent (cycle_start queues it, the actual send happens later in pre_send). So the read is the slave's own free-running DC SystemTime from before it received our epoch, exactly your speculation about the 0x92C offset register. lcec's unwrap code then seeds master->ref_time_ns = (app_time & 0xFFFFFFFF00000000) | 1,875,535,147.
2. Cycle 1 pre_send reads ref_time_lo = 1,037,346,343 (now valid, slave has received our app_time and rebased). The 32-to-64-bit wrap detector sees 1,037,346,343 < 1,875,535,147 and adds (1LL << 32) to master->ref_time_ns. False wrap.
3. With ref_time_ns now 4.3 billion ns ahead of dc_time_ns, the resnap logic in pre_send divides the diff by the period and snaps app_time backwards by 4295 periods. That's your +4.295e9 jump.
4. PI then only has to absorb the sub-period residual, which is why your cycle 3+ looks normal.
Fix is in v1.41.0-pre2. A ref_seeded flag discards the first nonzero read; the second nonzero read seeds the unwrap state without wrap detection; steady-state wrap detect takes over from cycle 2 onward.
After the fix on the same hardware:
# cycle pll_err ref_time_lo app_time_ns app_time_lo
0 0 3928128362 829970359148090426 4011856954
1 0 4043140737 829970359149090426 4012856954
2 -192285 4044085554 829970359181090426 4044856954
3 -187787 4045074812 829970359182090426 4045856954
...
No phantom 4.3sec. The cycle 1 to 2 delta is now 32 ms (32 periods), which is the real initial phase error between the slave's rebased SystemTime and our app_time at startup, snapped to whole periods by resnap. PI absorbs the ~190 us sub-period residual over the settle time. pll_reset_count stays at 0 because the first resnap fires with dc_diff_ns == 0 and skips the counter increment.
So your speculation about the slave maintaining its own time and adding an offset after rebase is consistent with what we observe. The lcec bug was specifically the wrap detector treating the pre-rebase read as the baseline for the post-rebase read.
R2M in the current master was already correct in this respect (no read, no bad baseline), so no change there.
Thanks again for the clear debug output, it was the whole reason this was easy to pin down.
Could you test my 1.41~pre2 release on GitHub, to confirm you get the same result?
github.com/grandixximo/linuxcnc-ethercat...ses/tag/v1.41.0-pre2
But be warned even with this fix the OP time in my case remain about the same, the hardware has to do OP to run in DC, and it does take time, I agree with Rob's assessment, having the first device on the network be a good DC device is a must if you want good DC, I could try to debug what is the problem with papagno's first device, and I am also trying to get Ethercat to fix the function where we will be allowed to move the DC reference to arbitrary devices in the network, at the moment this function is present in the API but does NOT work.
This is simply restart after few minutes LinuxCNC was closed (servos had time to drift apart)
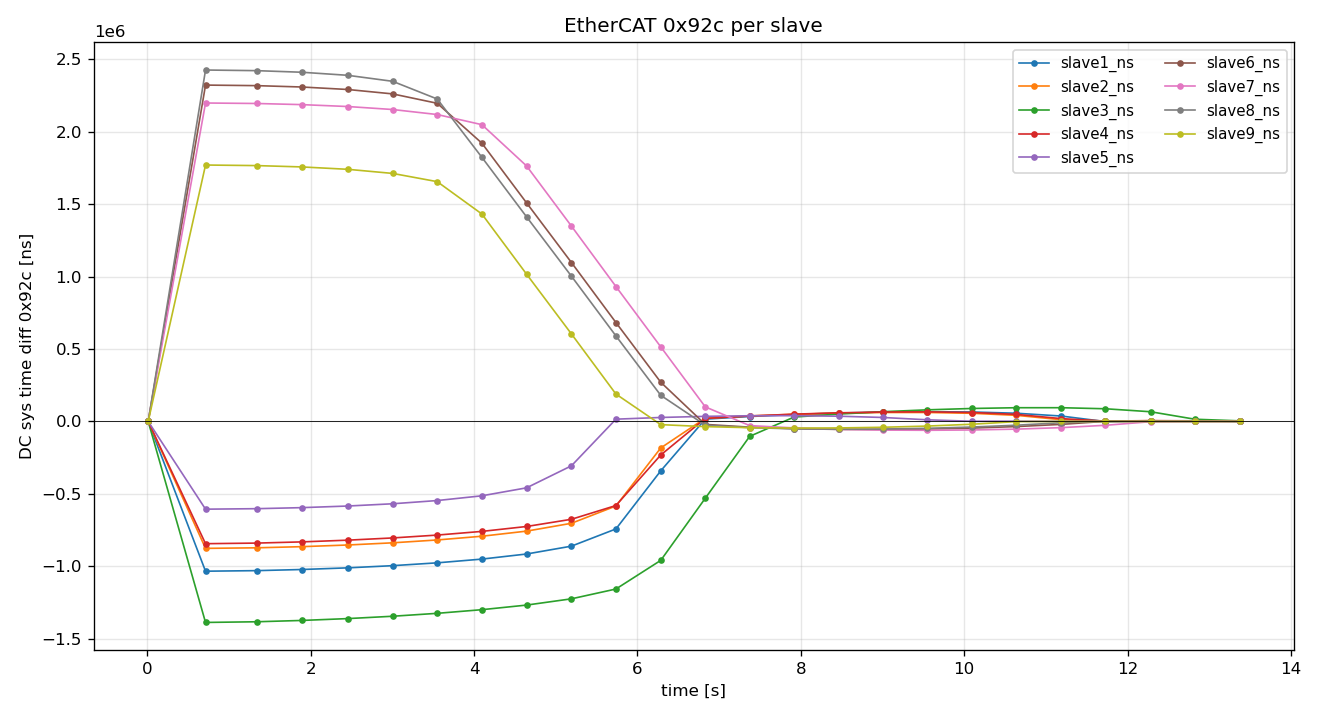
12s OP
Then quickly close and open again (servos had NO time to drift apart)
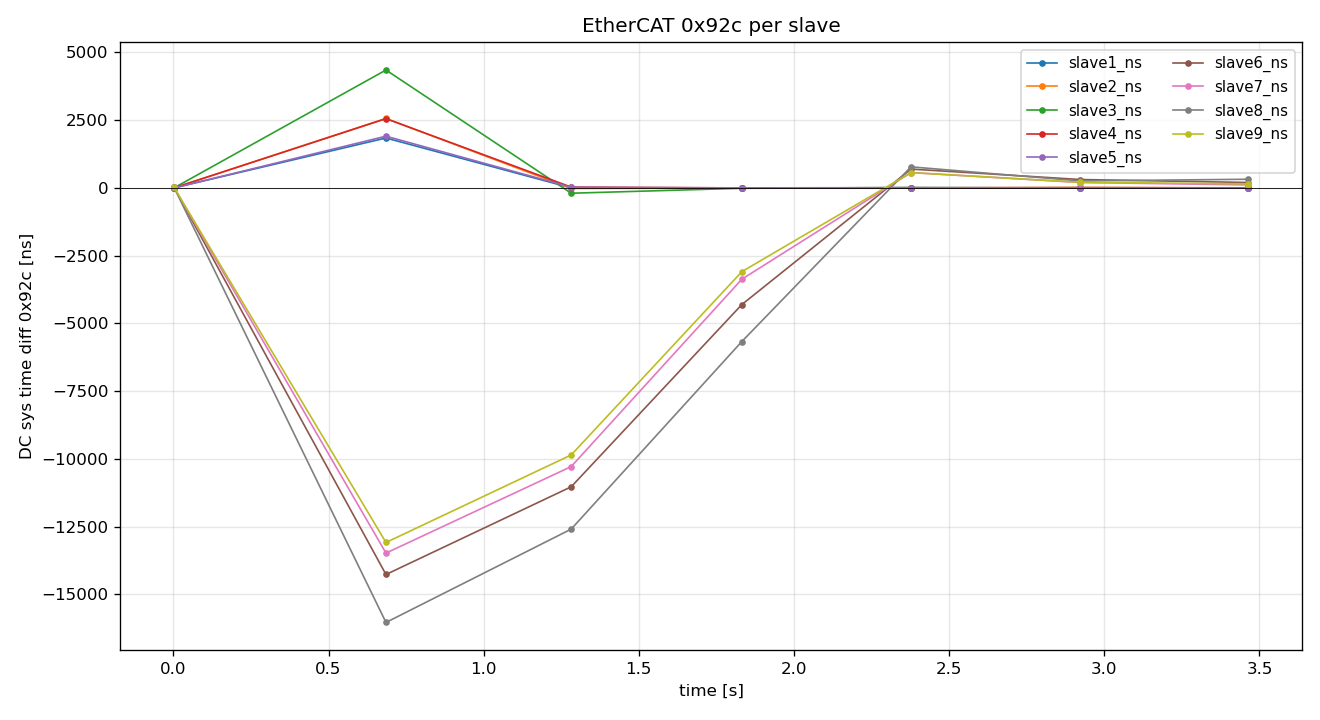
3s OP
if you want to get similar logs
As far as AssignActivate 0x300 to 0x730 I don't use this type of sync as i run in pos-cmd I don't think is necessary in my use case, but it should work, I think 0x300 should work fine for pos-cmd, if you use vel or torque command with internal PID you might want to look at 0x700 or 0x730
Attachments:
Please Log in or Create an account to join the conversation.
- papagno-source
- Offline
- Elite Member
-
- Posts: 170
- Thank you received: 13
Please Log in or Create an account to join the conversation.
- grandixximo
-
Topic Author
- Offline
- Elite Member
-
- Posts: 307
- Thank you received: 367
If you want to keep an I/O as first device I suggest EK1100 instead, or have the servos first.
If you want encoder for rigid tapping I suggest EL5152 and a suitable encoder with A/B/Z signals.
EL5122 does not support Z signal, and you'd have to create a virtual one, more laborious, and possibly never as precise/repetitive.
Using EL5122 or EL5152 as first device on DC also not advised, they are not conmonly used that way, so I'd avoid it.
I've been think about your debian 10 immediately OP, and I suspect that points to your debian 10 running in free mode and not DC.
Please Log in or Create an account to join the conversation.
- papagno-source
- Offline
- Elite Member
-
- Posts: 170
- Thank you received: 13
Exist a model one 5 volt TTL with 1 channel encoder or 2 channel encoder , with really Z index signal ?
Please Log in or Create an account to join the conversation.
- papagno-source
- Offline
- Elite Member
-
- Posts: 170
- Thank you received: 13
Please Log in or Create an account to join the conversation.
- grandixximo
-
Topic Author
- Offline
- Elite Member
-
- Posts: 307
- Thank you received: 367
Exist a model one 5 volt TTL with 1 channel encoder or 2 channel encoder , with really Z index signal ?
EL5101 is 5V with the Z index
Please Log in or Create an account to join the conversation.